In order to logically solve a problem, you must use tools to logically go through a solution. This is shown best with structured programming, where a program is abstracted into three different techniques:
These can help deconstruct a problem and are used especially when first designing e.g. with pseudocode, flow diagrams or trace tables.
Concurrently thinking is most similar to parralel thinking, although it does slightly diverge as parallel processing involves multiple processors splitting instructions between them,
whilst concurrent processing is where a single processor runs multiple instructions by periodically switching between them.
These both have their advantages and disadvantages:
Computable - where an algorithm can solve every instance of the problem in a finite number of steps
Although it would be best if all problems could be computable this isn't always the case so problem solving techniques are employed to find an algorithm that can try
Brute force - or enumeration where a problem is solved by an exhaustive search for the solution. Although guarantees a solution is most often ineffective
Simulation - where a real life problem is abstracted and modelled, to be more easily tested
Divide and Conquer - where each search for the solution reduces the search size (binary search halving each iteration)
Abstraction - Removing unnecessary details until the solution is more easily computed
Automation - building models to solve problems through simulation and testing
To develop an algorithm to solve a problem, the programmer must consider first a logical way to solve it, then how to implement this is code and then its time complexity
Backtracking - methodically solve a problem by trying solutions without knowing what's the best solution, what some decisions might lead to or if there are multiple solutions
Data mining - digging through Big data to discover hidden connections and create simulations for prediction
Time complexity is an important issue when creating an algorithm as, even if a problem is computable, it might be intractable - it would take to long to reasonably solve the problem.
This is the main issue with the brute force approach, as despite often being the easiest to implement they often have intractable time complexities (n!)
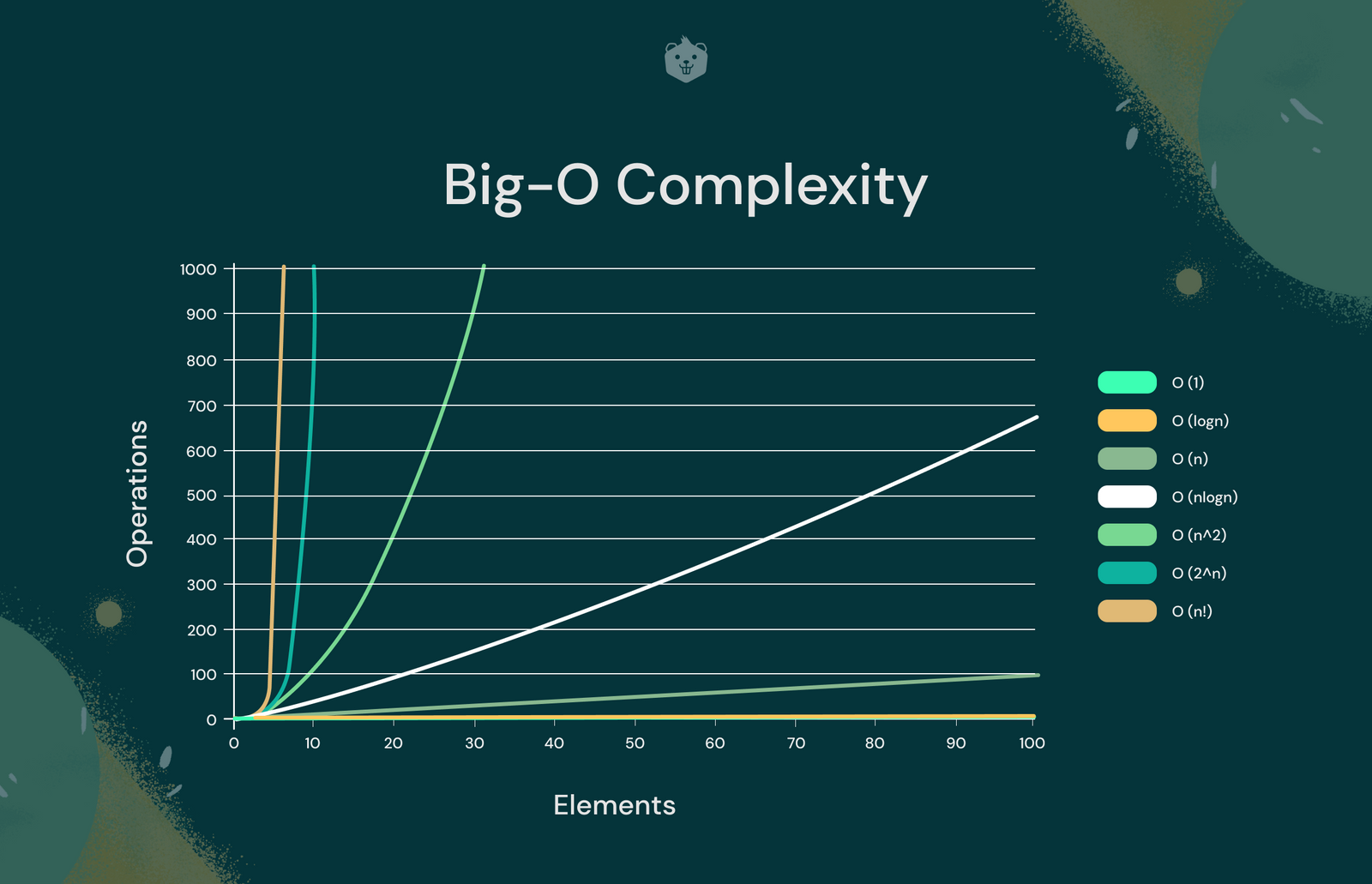
In order to decrease the time complexity of some problems, it might be more efficient to go for the heuristic approach - where the algorithm calculates an optimal solution but not the best.
This can make a previously intractable problem have a reasonable time complexity for more implementation, focusing on speed rather than the best solution.
Performance modeling - where an algorithm or computer is tested using a model rather than an actual performance test if this is difficult
Pipelining - splitting a task into smaller sections and processing each part in parralel using parralel or concurrent processing, so that instructions cna be executed whilst new ones fetched or decoded